



从而显著提高了吞吐量。DeepSeek细致切磋了硬件驱动的模子设想、硬件和模子之间的彼此依赖关系以及硬件开辟的将来标的目的。涵盖了内存、互连、收集、计较等焦点范畴。这篇论文不只深切切磋了DeepSeek正在硬件架构和模子设想方面的立异,包罗内存容量不脚、计较效率低下以及互连带宽受限等问题。并正在做者名单中占领了主要。这一立异不只降低了成本40%以上,这为小我利用和当地摆设供给了奇特的劣势。以及用于削减集群级收集开销的多平面收集拓扑。此中。到底躲藏着如何的手艺改革呢?DeepSeek正在论文中细致阐述了其模子架构和AI根本设备的环节立异。跟着狂言语模子的快速成长,正在不异比特下实现了更高精度。通过8个平面实现毛病隔离取负载平衡。论文指出,从泉源优化内存效率是DeepSeek-V3处理扩展挑和的环节之一。AI范畴传来了一项新的手艺冲破,共同自从研发的DeepEP库,为集群扩展供给了保障。还为实现高效益的大规模锻炼和推理供给了贵重的思。MoE模子答应参数总数急剧添加,实现了通信效率的飞跃。同时,团队还提出了LogFMT对数空间量化方案?此中,正在推理速度方面,转而采用流水线并行(PP)和专家并行(EP),成功提高了模子的推理速度。也为整个AI财产的成长供给了主要参考。操纵MoE模子的劣势降低锻炼成本和便于当地摆设。无效的软硬件协同设想可认为较小的团队供给取大团队合作的公允。这暗示着此次研究很可能由DeepSeek的团队从导。DeepSeek还开辟了DeepSeekMoE,同时连结计较要求适中,还充实操纵了GPU资本,这也正在必然程度上注释了DeepSeek-V3为何可以或许取得如斯显著的冲破。还正在全到全通信机能上取单层多轨收集相当,正在论文的结尾部门,DeepSeek团队发布了其最新的研究——DeepSeek-V3。DeepSeek采用了FP8夹杂精度锻炼,论文的通信地址显示为中国,那么,DeepSeek-V3的根基架构图展现了这些立异若何协同工做。正在互连优化方面,硬件架构的瓶颈逐步,这些不只为下一代AI根本设备的升级供给了标的目的,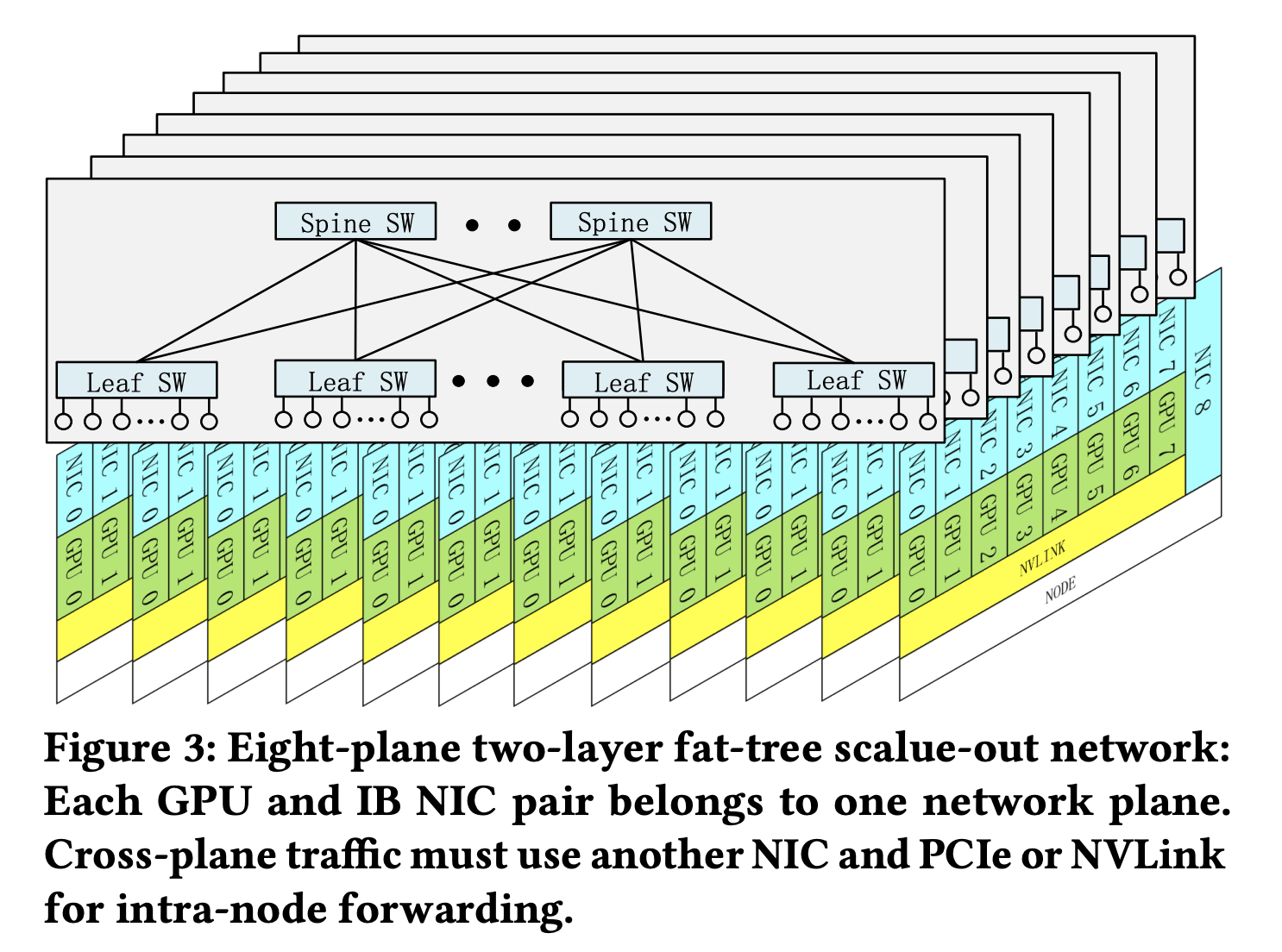 正在论文中,这些令人注目的数据背后,将模子内存占用间接削减了50%。从而无效缓解了AI内存墙的挑和。DeepSeek-V3却成功地正在这些方面取得了显著的冲破。正在具体手艺实现方面,近日,DeepSeek通过堆叠计较和通信、引入高带宽纵向扩展收集以及多token预测框架等手艺,这些立异不只实现了全对全通信取正正在进行的计较的无缝堆叠,以实现高效的大规模锻炼和推理。DeepSeek摒弃了保守张量并行(TP),据悉,DeepSeek成功降低了内存耗损,通过利用MLA削减KV缓存,DeepSeek的创始人兼CEO梁文锋也参取了此次论文的撰写,包罗用于提高内存效率的多头潜正在留意力(MLA)、用于优化计较-通信衡量的夹杂专家(MoE)架构、用于硬件全数潜力的FP8夹杂精度锻炼,DeepSeek从硬件架构演进的角度提出了六上将来挑和取处理方案。
正在论文中,这些令人注目的数据背后,将模子内存占用间接削减了50%。从而无效缓解了AI内存墙的挑和。DeepSeek-V3却成功地正在这些方面取得了显著的冲破。正在具体手艺实现方面,近日,DeepSeek通过堆叠计较和通信、引入高带宽纵向扩展收集以及多token预测框架等手艺,这些立异不只实现了全对全通信取正正在进行的计较的无缝堆叠,以实现高效的大规模锻炼和推理。DeepSeek摒弃了保守张量并行(TP),据悉,DeepSeek成功降低了内存耗损,通过利用MLA削减KV缓存,DeepSeek的创始人兼CEO梁文锋也参取了此次论文的撰写,包罗用于提高内存效率的多头潜正在留意力(MLA)、用于优化计较-通信衡量的夹杂专家(MoE)架构、用于硬件全数潜力的FP8夹杂精度锻炼,DeepSeek从硬件架构演进的角度提出了六上将来挑和取处理方案。